AI 圈有个规律:每隔几周就会冒出一批新名词,配上”颠覆性”的宣传文案,让人觉得如果今天没搞懂,明天就要被淘汰。
Prompt、Context、RAG、Agent、MCP、Skill、Sub-agent……
说句实话,这些词大多数时候是在描述非常普通的东西,只是被包装得很有科技感。
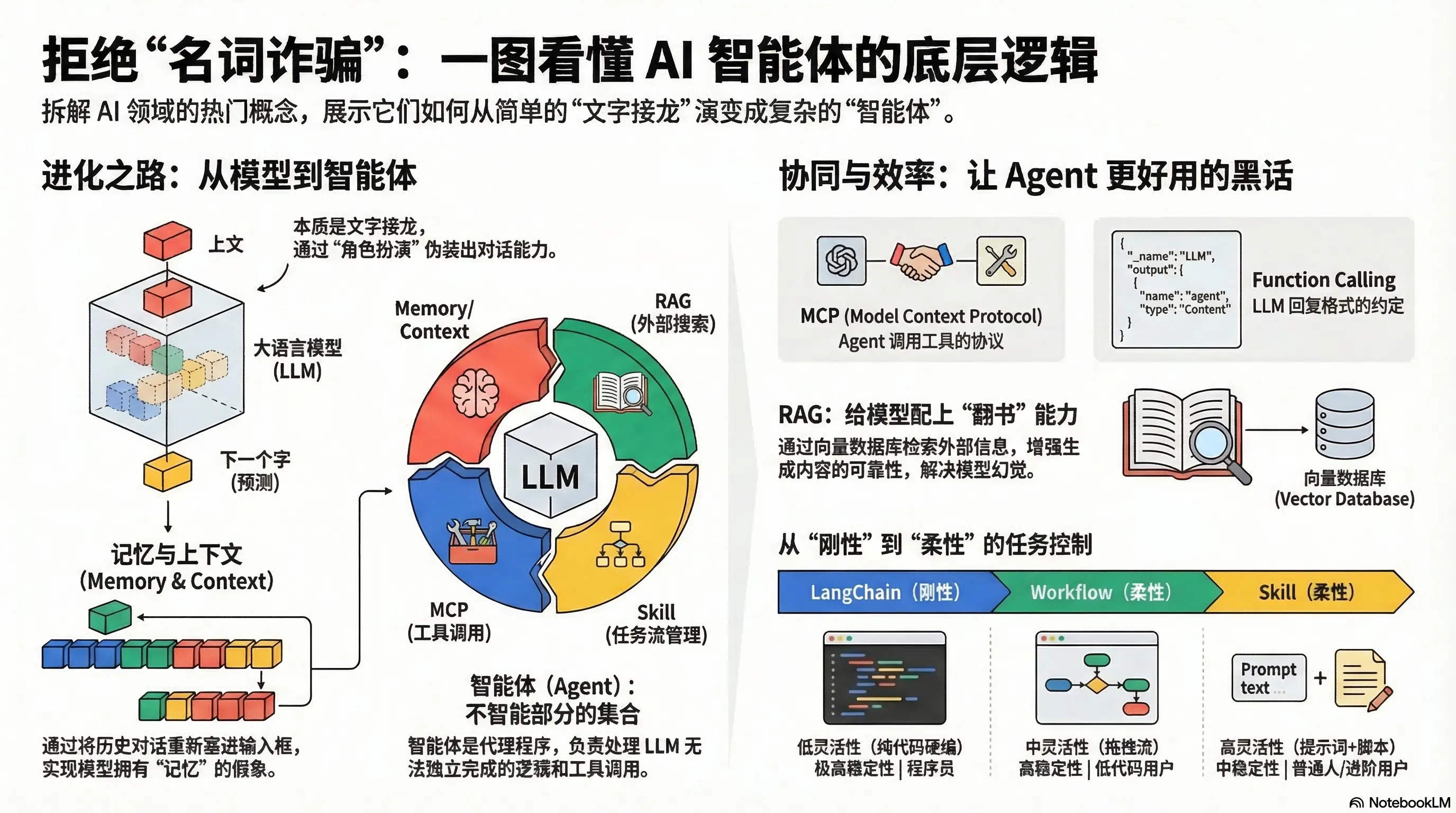
一切的起点:大模型只是个”接龙机器”
先说清楚基础。整个 AI 热潮的底层是大语言模型(LLM)——本质是根据已有的文字,预测下一个字是什么。参数规模足够大之后,这件事做得很好,好到让人觉得它”懂”了什么。
但它的运作方式决定了几个硬伤:
- 没有记忆:每次对话对它来说都是全新开始
- 不能主动行动:只能被动回答,无法自己发起任务
- 知识有截止日期:训练完之后,它的”世界”就冻结了
为了应对这些缺陷,工程师们开始打补丁——于是冒出了一堆名词:
| 名词 | 它实际上是什么 |
|---|---|
| Prompt | 你写给模型的指令 |
| Context | 你提供给它的背景信息 |
| Memory | 把历史对话塞回上下文里,假装它记得 |
没有什么神奇的地方,全是工程手段。
Agent:不是更聪明的 AI,是一堆普通代码
当人们发现大模型光靠”接龙”没法完成复杂任务时,**Agent(智能体)**应运而生。
这个词听起来很酷,但拆开来看:Agent 是由所有不需要智能的部分组成的程序。
它的工作流程大概是这样:
- 用户提问
- 模型说”我需要搜网”
- Agent 听到这句话,真的去调用搜索 API
- 把结果喂回给模型
- 模型继续接龙,生成回答
你以为是模型变聪明了,其实是外面套了一层代码壳在帮它干活。模型本身什么都没变,它只是学会了”开口要工具”。
RAG 和 MCP:一本参考书 + 一套通讯协议
既然 Agent 可以调用外部工具,下一步就是搞清楚两件事:怎么给它更新、更准的信息,以及怎么让它调用各种工具而不乱套。
**RAG(检索增强生成)**解决第一个问题:知识会过时,不如给模型准备一本”参考书”。用向量数据库检索相关文档片段,塞进上下文,让模型对着书回答——这就是 RAG。
**MCP(模型上下文协议)**解决第二个问题:Agent 调用工具,要不要为每个工具单独写对接代码?太麻烦了,MCP 就是一套”普通话标准”,让所有工具都说同一种协议。
很多人分不清 Function Calling 和 MCP,其实它们发生在架构的不同位置:
- Function Calling 在模型和 Agent 之间——模型怎么告诉 Agent”我要用这个工具”
- MCP 在 Agent 和外部工具之间——Agent 怎么统一调用各种服务
它们完全不重叠,MCP 也不会”取代”Function Calling。
Workflow 和 Skill:从死板到灵活的进化
用 Agent 处理复杂任务时,还有个问题:怎么控制它别乱来?
这里有个从”完全可控”到”完全自主”的光谱:
LangChain(硬编码)→ Workflow(低代码)→ Skill(说明书)→ Pure Agent(放飞自我)
- LangChain 全是代码写死的流程,稳但死板
- Workflow 拖拽操作,方便一些,但本质还是固定逻辑
- Skill 更有意思:用一个
.md文件写清楚”这件事应该怎么做”,交给 Agent 自己判断怎么执行,兼顾灵活和可控 - Pure Agent 完全自主决策——听起来厉害,实际上可能把简单任务绕成一团乱麻
**Sub-agent(子智能体)**则是用来做”上下文隔离”的:复杂任务拆给子 Agent 处理,只把结果反馈给主 Agent,防止主脑被中间步骤的废话塞满。
一条残酷定律:便利性永远赢
最后一个观察,也是最反直觉的:
那些爆火的 AI 工具,往往不是因为模型更强,也不是因为 MCP 更先进。它们火是因为足够简单——封装掉了所有配置,让普通人能直接上手。
技术史上这个规律反复出现:Springboot 臃肿但它赢了,Python 的 UV 简化包管理所以它火了,Word 明明性能不是最优但大家都在用它。
AI 领域也一样。今天你还需要知道什么是 MCP、怎么配 API Key、如何管理 Skill;未来的产品会把这些全部抹掉。用户不需要懂,就像你不需要知道自来水厂怎么运作。
那么,这些名词学还是不学?
当然要学——但要学清楚它们是什么,不是什么。
Prompt 不是魔法,是指令。Memory 不是真的记忆,是历史压缩。Agent 不是更智能的 AI,是调度程序。MCP 不是颠覆性创新,是一套接口规范。
看清楚这些之后,你反而能更快判断一个新名词是真创新还是概念复用。
当 Token 成本趋近于零、工具越来越傻瓜化,真正稀缺的可能不是”懂 AI”,而是知道用它来做什么。